Clean up property owner names
 A house for lease in Southern Chase in Concord, N.C., April 26, 2022. // Khadejeh Nikoyeh, The Charlotte Observer
A house for lease in Southern Chase in Concord, N.C., April 26, 2022. // Khadejeh Nikoyeh, The Charlotte Observer
One of the files resulting from The Charlotte Observer and The News & Observer’s investigation is a “lookup table” – basically just a spreadsheet that can help us match the hundreds of subsidiaries and holding companies big corporate landlords use to buy and manage property with their respective parent firms.
These holding companies can sometimes be distinct entities, or they can just be mistyped into the property record system.
Either way, the text in your property records must be an exact match to one of the firms in our lookup table, or it won’t match to a corresponding parent company.
In this walkthrough, you’ll learn how to:
- Import data in R
- Create custom functions
- Execute custom functions with different parameters
Prepare your data
For this walkthrough, you’ll need two main datasets:
- The property record data for your market (we’ll be using Wake County, N.C.)
- If this file isn’t available online for your county, city or state, you may need to request it, probably from your local register of deeds. Example: Wake County real estate data
- Make sure you get the field layout/data dictionary that describes the columns of the data. Example: Wake County record layout
- The corporate landlord lookup spreadsheet created by The Charlotte Observer/The News & Observer
Store both of these files in the working directory containing your R project file (Skip that step? Review the Setting Up tutorial).
Take note of the filetype extension. Is it a comma-separate value, or CSV? A text file with data defined by its position on each line (a fixed-width file)? Or is it a giant Excel file (.xlsx)? Depending on the filetype, you’ll have to use slightly different import options below.
Take note of which column contains the property owner name in your property record database. Some datasets may split this into a first name and last name for individuals (but not for corporate entities, which is what we care about), or across multiple columns if there are multiple owners.
In our Wake County data, our property owner name is contained in the OWNER1 column and is not split by first and last name. We’ll note that for later.
Getting started
Start RStudio and in the top menu, click File > Open Project... and select the R Project file you started. This will automatically change your working directory.
Then start a new R script by clicking File > New File > R Script and click File > Save As... to name your work. We’re going to call ours clean_names.R.
If everything is where it’s supposed to be, you’ll notice your Files pane should include your script, your R project and the data files you stored in your directory. Check to make sure everything’s here.
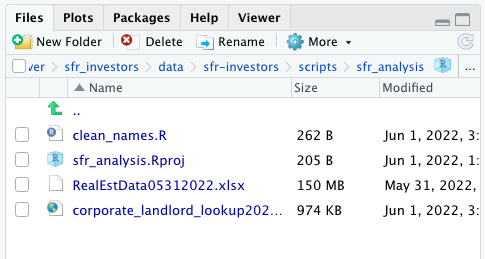
At the top of your script, write a quick comment that tells you something about what your new script does. Starting each line with a # character will ensure this line is not executed when you run your code.
# A script containing cleaning steps for owner names
# in property records data
# created 6/1/2022 by @mtdukes
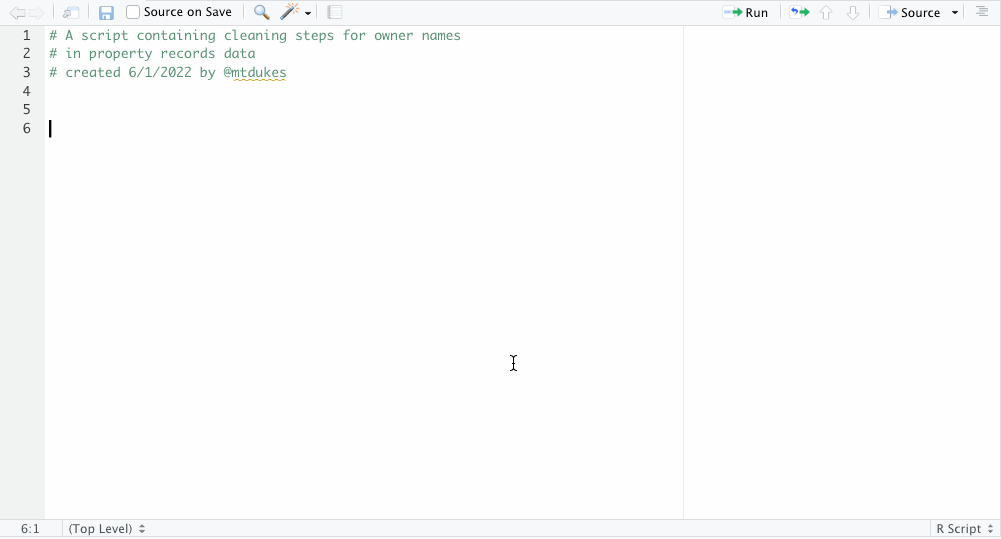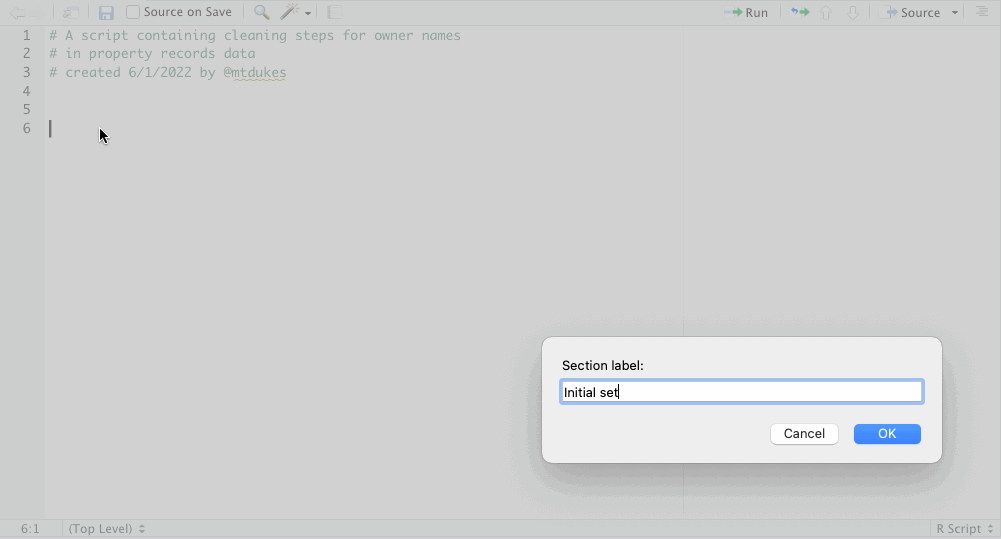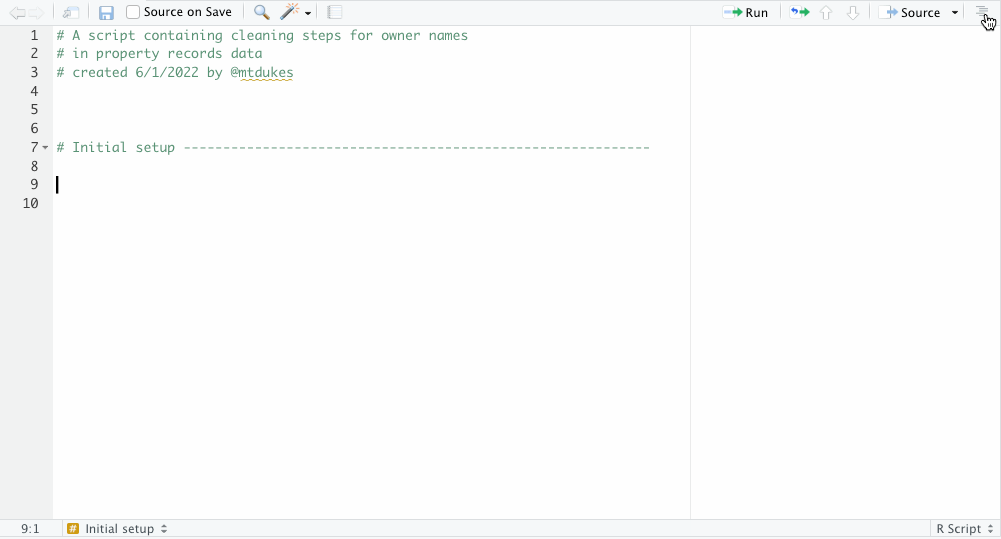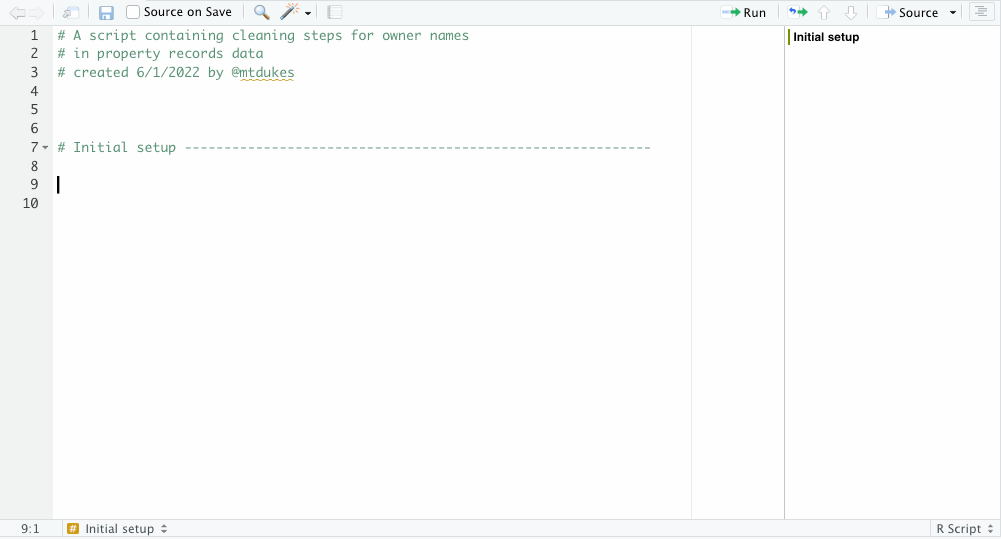
For organizational purposes, create a section label with the keyboard shortcut Command + Shift + R. Section labels are visible in the Document Outline, which you can toggle with the button in the upper right of the script pane. Using section labels allows you to navigate through sections of your code with a point and click.
Use them whenever it makes sense as you organize your code.
Here, we’ll do some initial setup, like loading up our packages into our workspace if they’re already installed.
#load up our packages
library(tidyverse)
library(readxl)
Remember: Execute each line of code by clicking Run or with CMD + Enter.
Importing your data
Your next step depends on what type of property records file you’re importing. Click to jump to directly to the corresponding instructions:
- Excel file (.xlsx extension)
- Fixed-width file (.txt extension with a set number of characters per line)
- Comma-separated value file (.csv extension)
- Tab-delimited file (.tsv extension or .txt extension with tabs between columns)
The code blocks below are examples based on the data we’re using from Wake County. You’ll have to adjust for your specific dataset.
A.) Importing an Excel file
The readxl package, part of the Tidyverse, makes it pretty easy to import Excel files into R.
We’ll use the read_excel() function from that package to store the resulting dataframe in a variable with the assignment symbol, <-. You can use the keyboard shortcut Option + - to input that symbol at your cursor.
#import xlsx of wake county property records
wake_properties <- read_excel('RealEstData05312022.xlsx')
JUMP TO THE NEXT STEP
B.) Importing a fixed-width file
Tidyverse has a specific function for importing fixed-width files called read_fwf(). It does require a bit of extra code, since you’re having to explicitly tell the function where each field begins and ends. Consult the field layout for your dataset to help you.
Use the assignment symbol, <-, to store your imported data to a variable. You can use the keyboard shortcut Option + - to input that symbol at your cursor.
When we load the data, we’ll go ahead and assume everything is a character string (letters and numbers that R treats as plain text) to reduce import errors.
#import fwf of wake county property records
wake_properties <- read_fwf('RealEstData06012022.txt',
trim_ws = TRUE, #trim errant white space
fwf_cols(owner_1 = c(1, 35), #positions based on data dictionary
owner_2 = c(36, 70),
mailing_address_1 = c(71, 105),
mailing_address_2 = c(106, 140),
mailing_address_3 = c(141, 175),
real_estate_id = c(176, 182),
card_number = c(183, 185),
number_of_cards = c(186, 188),
street_number = c(189, 194),
street_prefix = c(195, 196),
street_name = c(197, 221),
street_type = c(222, 225),
street_suffix = c(226, 227),
planning_jurisdiction = c(228, 229),
street_misc = c(230, 234),
township = c(235, 236),
fire_district = c(237, 238),
land_sale_price = c(239, 250),
land_sale_date = c(251, 260),
zoning = c(261, 265),
deeded_acreage = c(266, 273),
total_sale_price = c(274, 284),
total_sale_date = c(285, 294),
assessed_building_value = c(295, 305),
assessed_land_value = c(306, 316),
parcel_identification = c(317, 335),
special_district_1 = c(336, 338),
special_district_2 = c(339, 341),
special_district_3 = c(342, 344),
billing_class = c(345, 345),
property_description = c(346, 385),
land_classification = c(386, 386),
deed_book = c(387, 392),
deed_page = c(393, 398),
deed_date = c(399, 408),
vcs = c(409, 415),
property_index = c(416, 455),
year_built = c(456, 459),
no_of_rooms = c(460, 465),
units = c(466, 471),
heated_area = c(472, 482),
utilities = c(483, 485),
street_pavement = c(486, 486),
topography = c(487, 487),
year_of_addition = c(488, 491),
effective_year = c(492, 495),
remodeled_year = c(496, 499),
unused = c(500, 501),
special_write_in = c(502, 509),
story_height = c(510, 510),
design_style = c(511, 511),
foundation_basement = c(512, 512),
foundation_basement_pct = c(513, 514),
exterior_wall = c(515, 515),
common_wall = c(516, 516),
roof = c(517, 517),
roof_floor_system = c(518, 518),
floor_finish = c(519, 519),
interior_finish = c(520, 520),
interior_finish_1 = c(521, 521),
interior_finish_1_pct = c(522, 523),
interior_finish_2 = c(524, 524),
interior_finish_2_pct = c(525, 526),
heat = c(527, 527),
heat_pct = c(528, 529),
air = c(530, 530),
air_pct = c(531, 532),
bath = c(533, 533),
bath_fixtures = c(534, 536),
built_in_1_description = c(537, 551),
built_in_2_description = c(552, 566),
built_in_3_description = c(567, 581),
built_in_4_description = c(582, 596),
built_in_5_description = c(597, 611),
city = c(612, 614),
grade = c(615, 619),
assessed_grade_difference = c(620, 622),
accrued_assessed_condition_pct = c(623, 625),
land_deferred_code = c(626, 626),
land_deferred_amount = c(627, 635),
historic_deferred_code = c(636, 636),
historic_deferred_amount = c(637, 645),
recycled_units = c(646, 651),
disqualifying_qualifying_flags = c(652, 652),
land_disqualify_qualify_flag = c(653, 653),
type_use = c(654, 656),
physical_city = c(657, 706),
physical_zip_code = c(707, 711)
),
col_types = cols(.default = col_character()) #import data as characters
)
JUMP TO THE NEXT STEP
C.) Importing a CSV file
Use the Tidyverse function read_csv() to import a comma-separate value file, storing it in a variable with the assignment symbol, <-. You can use the keyboard shortcut Option + - to input that symbol at your cursor.
When we load the data, we’ll go ahead and assume everything is a character string (letters and numbers that R treats as plain text) to reduce import errors.
#import a csv of wake county property records
wake_properties <- read_csv('RealEstData06012022.csv',
col_types = cols(.default = col_character()) #import data as characters
)
JUMP TO THE NEXT STEP
D.) Importing a tab-delimited file
Use the Tidyverse function read_csv() to import a comma-separate value file, storing it in a variable with the assignment symbol, <-. You can use the keyboard shortcut Option + - to input that symbol at your cursor.
When we load the data, we’ll go ahead and assume everything is a character string (letters and numbers that R treats as plain text) to reduce import errors.
#import a tsv of wake county property records
wake_properties <- read_tsv('RealEstData06012022.tsv',
col_types = cols(.default = col_character()) #import data as characters
)
JUMP TO THE NEXT STEP
Regardless of the method you use, this may take a few minutes, depending on the size of your property record file. You should see the data show up in your Environment pane in the top right.
Take note of any error messages or warnings, as these may be the result of import errors that can skew your analysis.
Importing the lookup table
The Observer/N&O lookup table is provided as a CSV file, so we’ll use read_csv() to import it.
#import the corporate lookup table
investors_labeled <- read_csv('corporate_landlord_lookup202204301254.txt')
If both datasets imported correctly, you should see them in your Environment pane, where you you can click to view them as tables.
Understanding functions in R
To clean up our owner name column and increase our chances of getting matches, we’ll need to use a few custom functions. A function is just a set of generalizable instructions we can use again and again (say, on hundreds of thousands of dirty owner names).
R has lots of built-in functions already, and we’ve already used a few of them.
Here’s a basic example of a custom function and its syntax. We assign the function to a variable, effectively naming it. We specify the parameters and use curly brackets ({ }) to contain our actual instructions. In this case, we’ll return the resulting value.
# a simple custom that adds two numbers and returns the result
# usage:
# addTwoNumbers(4, 8)
addTwoNumbers <- function(number1, number2){ #assign our function and specify parameters
result <- number1 + number2 #do the addition
return(result) #return the result
}
Executing this code block doesn’t appear to do much – except you should see your addTwoNumbers() function under “Functions” in your Environment pane.
Now you can execute the function by including two numbers as the parameters for the function.
# execute our custom addition function
addTwoNumbers(4, 8)
This may not seem terribly exciting now – we can already add numbers, after all. But it hints at something really powerful: Writing our own functions to perform specific tasks means we don’t have to write the same code over and over again.
Defining cleanup functions
The Observer/N&O team used a series of custom functions to standardize the cleanup process on owner names, which we used for both the property data and the lookup table.
Basic text cleanup
The first two are designed to strip white space and punctuation from the names (there are some functions in R that exist to do this, but we wanted full control over the process). But the functions do make use of a package within the tidyverse called stringr, which makes working with character strings a little easier, as well as regular expressions, a way to create search patterns in text.
Execute the following code to store the functions in your workspace.
#utility function for stripping punctuation from a string
#
#usage
#stripPunctuation('you, wot @$mate")whooo* ')
stripPunctuation <- function(string){
stripped_string <- string
stripped_string <- str_replace_all(stripped_string, '[[:punct:][:blank:]]+', ' ')
stripped_string <- str_replace_all(stripped_string, '`','')
stripped_string <- str_replace_all(stripped_string, '\\$','S')
return(stripped_string)
}
#utility function for stripping white space from a string
#
#usage
#stripWS(' wooo lkj;lkj sdaf ddd ')
stripWS <- function(string){
stripped_string <- string
stripped_string <- str_replace_all(str_trim(stripped_string), '\\s+', ' ' )
return(stripped_string)
}
Once they’re loaded, you can test them to make sure they’re working as expected. You can even chain them together if you want
# test our punctuation stripper
stripPunctuation('you, wot @$mate")whooo* ')
# test our white space stripper
stripWS(' wooo lkj;lkj sdaf ddd ')
#chain them together with a pipe
'you, wot @$mate")whooo* ' %>%
stripPunctuation() %>%
stripWS()
Dealing with company names
Our experience pouring through millions of lines of property ownership data shows us that there is a lot of variation – misspellings, repetition, truncated text – that we’ll need to account for.
One of the most common issues is variation in the company entity type: limited liability corporation, limited partnership, etc.
We’re taking a brute force approach here. We tried to think of and catch all the variations we saw in our data, then wrote code to replace those variations with a set of “normalized” company entity types. But because we wrote it into a function, it runs efficiently – and if we need to catch something new, all we have to do is alter our function instead of changing it in multiple places.
# utility to fix up our corporation name entity types
#
# usage
# normalizeCorp('ACME CORPORATION')
normalizeCorp <- function(string){
#create a new variable
cleaned_string <- string
#shorten corporation
cleaned_string = str_replace_all(cleaned_string, '\\bCORPORATION\\b', ' CORP ')
#shorten company
cleaned_string = str_replace_all(cleaned_string, '\\bCOMPANY\\b', ' CO ')
#shorten incorporated
cleaned_string = str_replace_all(cleaned_string, '\\INCORPORATED\\b', ' INC ')
#take care of any spaced LPs
cleaned_string = str_replace_all(cleaned_string, '\\bL +P\\b', ' LP ')
#take care of any cut off limited partnerships
cleaned_string = str_replace_all(cleaned_string, '\\bLIMITED +PARTNERSHIP\\b', ' LP ')
cleaned_string = str_replace_all(cleaned_string, '\\bLIMITED +PARTNERSHI$', ' LP ')
cleaned_string = str_replace_all(cleaned_string, '\\bLIMITED +PARTNERSH$', ' LP ')
cleaned_string = str_replace_all(cleaned_string, '\\bLIMITED +PARTNERS$', ' LP ')
cleaned_string = str_replace_all(cleaned_string, '\\bLIMITED +PARTNER$', ' LP ')
cleaned_string = str_replace_all(cleaned_string, '\\bLIMITED +PARTNE$', ' LP ')
cleaned_string = str_replace_all(cleaned_string, '\\bLIMITED +PARTN$', ' LP ')
cleaned_string = str_replace_all(cleaned_string, '\\bLIMITED +PART$', ' LP ')
cleaned_string = str_replace_all(cleaned_string, '\\bLIMITED +PAR$', ' LP ')
cleaned_string = str_replace_all(cleaned_string, '\\bLIMITED +PA$', ' LP ')
cleaned_string = str_replace_all(cleaned_string, '\\bLIMITED +P$', ' LP ')
cleaned_string = str_replace_all(cleaned_string, '\\bLIMITED$', ' LP ')
cleaned_string = str_replace_all(cleaned_string, '\\bLIMITE$', ' LP ')
cleaned_string = str_replace_all(cleaned_string, '\\bLIMIT$', ' LP ')
cleaned_string = str_replace_all(cleaned_string, '\\bLIMI$', ' LP ')
#always the possibility we pull in someone with this as a last or first name
#so don't go furhter than the last three letters
cleaned_string = str_replace_all(cleaned_string, '\\bLIM$', ' LP ')
#remove any duplicated LPs
cleaned_string = str_replace_all(cleaned_string, '( +LP\\b){2,}', ' LP ')
#take care of any spaced LLCs
cleaned_string = str_replace_all(cleaned_string, '\\bL +L +C\\b', ' LLC ')
#take care of any cut off LLCs at the end
cleaned_string = str_replace_all(cleaned_string, '\\bLL$', ' LLC')
cleaned_string = stripWS(cleaned_string)
return(cleaned_string)
}
Execute the code block to store the function and test it.
# test our normalization function for companies
normalizeCorp('ACME CORPORATION')
Creating a ‘column cleaner’ function
Now let’s put it all together.
We’re going to create one more function that combines our three previous functions into one. This time, we’ll accept a few more parameters:
- df The dataframe (table) of data we want to clean
- field_string The column containing the property owner name we want to clean
- .clean_comp Optional. A logical (true/false) parameter telling our function whether we want to normalize company entity types. By default, this is turned off.
- .rm_stop Optional. A logical (true/false) parameter telling our function whether we want to remove a list of “stop words.” More on this later. By default, this is turned off.
Because this particular function takes some time to run depending on the size of your data, we also built in some feedback that prints to the console telling you what the function is doing and how long it took to run.
Execute the code block to store the function in your workspace.
# utility function to clean a specified property owner column. accepts a dataframe
# and adds a cleaned column. By default, only basic cleaning steps are enabled.
#
# usage
# clean_column(wake_properties, 'OWNER1', .clean_comp = TRUE)
clean_column <- function(df, field_string, .clean_comp = FALSE, .rm_stop = FALSE, .custom_geo = NULL){
start_time <- proc.time()[[3]]
#create new objects from strings we can use in dyplr syntax
field <- as.name(field_string)
field_clean <- as.name(paste0( field_string, '_clean' ))
cat('... STRIPPING PUNCTUATION...\n')
clean_names_df <- df %>%
select( all_of(field_string) ) %>%
unique() %>%
mutate( !!field_clean := toupper(!!field) ) %>%
mutate( !!field_clean := stripPunctuation(!!field_clean))
#normalize company entity types; default is skip
if(.clean_comp){
cat('... NORMALIZING COMPS...\n')
clean_names_df <- clean_names_df %>%
mutate( !!field_clean := normalizeCorp(!!field_clean))
}
#remove any stop words; default is skip
if(.rm_stop){
cat('... REMOVING STOP WORDS...\n')
#load in stop words
stop_words <- tibble(token = c('LLC','LL','CORPORATION','CORP','COMPANY','CO','INCORPORATED',
'INC','LLP','LP','PARTNERSHIP','PARTNERSHI','PARTNERSH','PARTNERS',
'PARTNER','PARTNE','PARTN','PART','PAR','PA','P','LIMITED',
'LIMITE','LIMIT','LIMI','LIM','LI','L','ASSOCIATION','ASSOC',
'ASSN','LTD','ASSC','HOLDINGS','HOLDING','PROPERTIES','BORROWER',
'OWNER','GROUP','1','2','3','4','5','6','7','8','9','10','11',
'12','13','14','15','16','17','18','19','20','I','II','III',
'IV','V','VI','VII','VIII','IX','X','A','B','C','D','E','F',
'G','H','J','K','M','N','O','Q','R','S','T','U','V','W','Y',
'Z','ONE','TWO','THREE','FOUR','FIVE','SIX','SEVEN','EIGHT',
'NINE','TEN','2011','2012','2013','2014','2015','2016','2017',
'2018','2019','2020','2021','NC','PROGRAM','PROPERTIES','PROPERTY')
)
#build a regex pattern with our stop words
pattern <- str_c('\\b', stop_words$token,'\\b', collapse = '|')
clean_names_df <- clean_names_df %>%
mutate( !!field_clean := str_replace_all(!!field_clean, '\\bNORTH CAROLINA\\b', 'NC') ) %>%
mutate( !!field_clean := str_replace_all(!!field_clean, pattern, '') )
}
#customize the geography; default is skip
if(length(.custom_geo) > 0){
cat('... CUSTOMIZING THE MARKET...\n')
if('state_abbr' %in% .custom_geo$type){
cat('... REPLACING STATE NAMES...\n')
state_abbr <- subset(.custom_geo, type == 'state_abbr')[[2]]
state_full <- subset(.custom_geo, type == 'state_full')[[2]]
clean_names_df <- clean_names_df %>%
mutate( !!field_clean := str_replace_all(!!field_clean, '\\bNORTH CAROLINA\\b', state_full) ) %>%
mutate( !!field_clean := str_replace_all(!!field_clean, '\\bNC\\b', state_abbr) )
}
if('city' %in% .custom_geo$type){
cat('... REPLACING CITY NAMES...\n')
# get our city names
cities <- subset(.custom_geo, type == 'city')[[2]]
#initialize a blank dataframe
added_cities_df <- clean_names_df %>%
head(0)
for(city in cities){
ral_df <- clean_names_df %>%
mutate( !!field_clean := str_replace_all(!!field_clean, '\\bRALEIGH\\b', city) )
clt_df <- clean_names_df %>%
mutate( !!field_clean := str_replace_all(!!field_clean, '\\CHARLOTTE\\b', city) )
added_cities_df <- added_cities_df %>%
rbind(ral_df) %>%
rbind(clt_df)
}
clean_names_df <- added_cities_df
}
}
#join our clean names column back with our original dataframe
clean_names_df <- df %>%
left_join(
clean_names_df,
by = field_string,
na_matches = 'never'
) %>%
relocate(!!field_clean, .after = !!field )
#strip white space after previous cleaning steps are complete
cat('... STRIPPING WHITE SPACE...\n')
clean_names_df <- clean_names_df %>%
mutate( !!field_clean := stripWS(!!field_clean))
cat('✓ CLEANING COMPLETE. ELAPSED TIME:', proc.time()[[3]] - start_time, 'seconds\n')
return(clean_names_df)
}
Like before, you should see your new function listed in the “Functions” section of your Environment pane.
Generating a clean owners in property records
Execute the code by piping your property record data into the function, making sure to specify the column name containing your property owner name – in our case, the column name is OWNER1 (make sure to offset the column name with quotes).
We’ll set .clean_comp to TRUE, so we can normalize the company entity types.
And we’ll store the output into a brand new table we’ll call wake_properties_clean.
# clean up our wake property owner names,
# normalizing the company entity type
# and store the result in a new table
wake_properties_clean <- wake_properties %>%
clean_column('OWNER1', .clean_comp = TRUE)
You should see a few lines of output in your console as the function runs. Depending on the size of your data, it may take a few minutes.
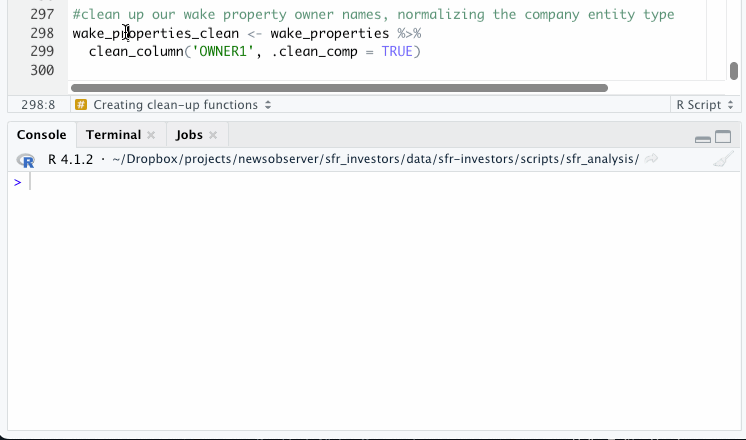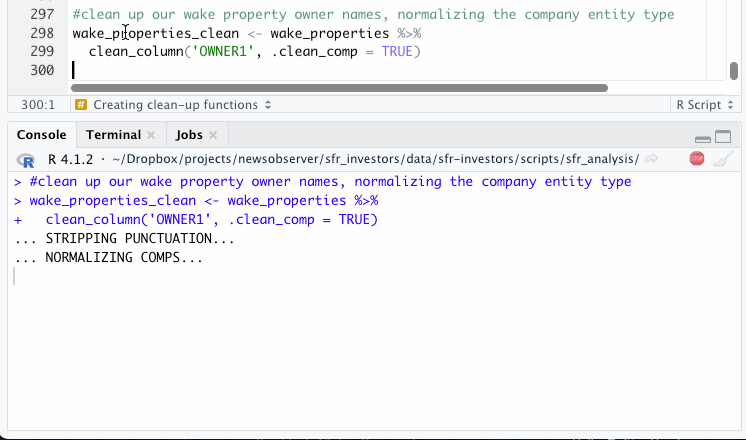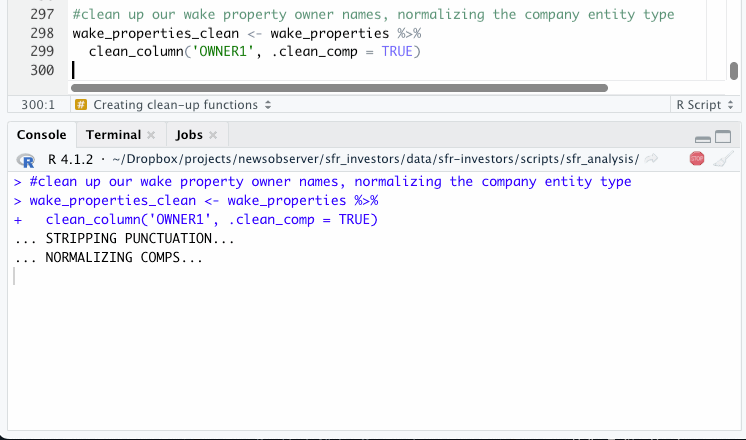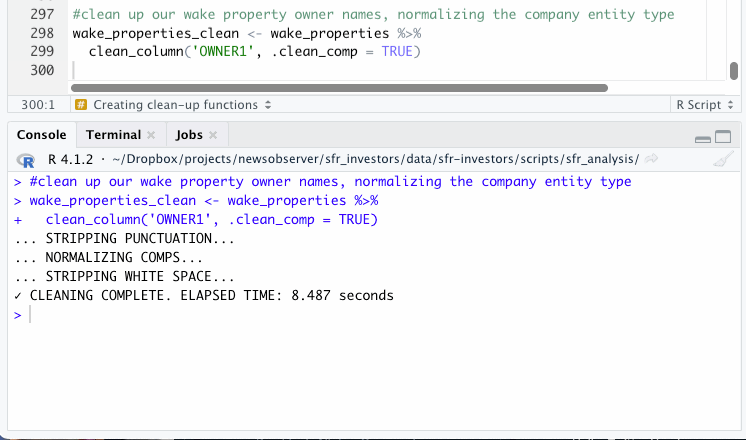
You should now see your new, cleaned dataframe in your Environment pane.
Customize your lookup table
We need to run a similar cleaning step for the lookup table. But before we do that, you’ll need to customize it for your market.
Why?
The Observer/N&O investigation focused on North Carolina and several specific cities. And during that process, we noticed that the holding companies and subsidiary names are often tied to region.
You can see this if you browse the data in the lookup table – lots of names include “North Carolina,” “NC,” “Charlotte,” and “Raleigh.” Use the tool below to select your state and add a few cities that you want to focus on. You can also remove the cities you enter if you change your mind.
When you’re done, click “Download custom list” to get a CSV file containing a small table we’ll use to customize our lookup table (you may need to disable popups).
Landlord lookup market customizer
Save the custom_geo_data.csv file you downloaded to your working directory. Once there, we’ll load it into our workspace.
#load in our custom geo data
custom_geo <- read_csv('custom_geo_data.csv')
Generating a clean owners in the lookup table
The steps we’ll use to clean up the names in our owners lookup table will look fairly similar to the processing we did to our property data, with one notable difference.
Instead of adding a whole new column with the “clean” name, we’re going to add the cleaned names as rows to the table. That way, we’re creating the biggest possible universe of potential matches based on the clean AND dirty versions of each name, which we’ll match to ONLY the clean names in our property table, increasing our chances of a match.
There are other ways to do this – fuzzy matching, for example – but that’s a bit outside the scope of our toolkit.
We can always cull the list down later (we would expect to do that in the fact-checking phase anyway).
We’ll run this in a few distinct steps, which we can chain together into one block of code.
In the third step, we’ll use our predefined cleaning function to remove “stop words” – common character strings that add a lot of unnecessary variation to the subsidiary names (many of the companies, for example, contain numbers, such as PROGRESS NC ONE, PROGRESS NC TWO etc.).
And in the final step, we’ll use your custom geographic market table to add in variations of the names for your state and/or cities.
So in order, here’s how we’ll clean the data, deduplicating between each step:
- Clean up punctuation and white space only
- Clean up punctuation and white space, then normalize the company entity type
- Clean up punctuation/white space, normalize company entity type, then remove stop words
- Replace any instances of North Carolina/NC cities with your market-specific states/cities, then rerun our previous steps.
We’ll store all of that cleaned data in a new table variable, so we can compare later if we need to.
Execute the following code to go through the cleanup process.
#our final, multi-step cleanup code
investors_clean <- investors_labeled %>%
#clean the owner column of punctuation and whitespace
clean_column('owner', .clean_comp = FALSE, .rm_stop = FALSE) %>%
gather(key = type, value = owner, -investor_label_lvl1, -investor_label_lvl2, -sos_name, -sos_id, -registry_url) %>%
select(owner, investor_label_lvl1, investor_label_lvl2, sos_name, sos_id, registry_url) %>%
distinct(owner, investor_label_lvl2, .keep_all = TRUE) %>%
#normalize company names types (LLC, LP, etc.)
clean_column('owner', .clean_comp = TRUE, .rm_stop = FALSE) %>%
gather(key = type, value = owner, -investor_label_lvl1, -investor_label_lvl2, -sos_name, -sos_id, -registry_url) %>%
select(owner, investor_label_lvl1, investor_label_lvl2, sos_name, sos_id, registry_url) %>%
distinct(owner, investor_label_lvl2, .keep_all = TRUE) %>%
#add in one more pass to remove stopwords
clean_column('owner', .clean_comp = FALSE, .rm_stop = TRUE) %>%
gather(key = type, value = owner, -investor_label_lvl1, -investor_label_lvl2, -sos_name, -sos_id, -registry_url) %>%
select(owner, investor_label_lvl1, investor_label_lvl2, sos_name, sos_id, registry_url) %>%
distinct(owner, investor_label_lvl2, .keep_all = TRUE) %>%
filter(!is.na(owner) & owner != '') %>%
#repeat each step for our city/state tweak
rbind(
investors_labeled %>%
select(-sos_name, -sos_id, -registry_url) %>% #remove our sos details
#CITY/STATE CUSTOM - clean the owner column of punctuation and whitespace
clean_column('owner', .clean_comp = FALSE, .rm_stop = FALSE, .custom_geo = custom_geo) %>%
gather(key = type, value = owner, -investor_label_lvl1, -investor_label_lvl2) %>%
select(owner, investor_label_lvl1, investor_label_lvl2) %>%
distinct(owner, investor_label_lvl2, .keep_all = TRUE) %>%
#CITY/STATE CUSTOM - normalize company names types (LLC, LP, etc.)
clean_column('owner', .clean_comp = TRUE, .rm_stop = FALSE, .custom_geo = custom_geo) %>%
gather(key = type, value = owner, -investor_label_lvl1, -investor_label_lvl2) %>%
select(owner, investor_label_lvl1, investor_label_lvl2) %>%
distinct(owner, investor_label_lvl2, .keep_all = TRUE) %>%
#CITY/STATE CUSTOM - add in one more pass to remove stopwords
clean_column('owner', .clean_comp = FALSE, .rm_stop = TRUE, .custom_geo = custom_geo) %>%
gather(key = type, value = owner, -investor_label_lvl1, -investor_label_lvl2) %>%
select(owner, investor_label_lvl1, investor_label_lvl2) %>%
distinct(owner, investor_label_lvl2, .keep_all = TRUE) %>%
filter(!is.na(owner) & owner != '') %>%
mutate(sos_name = NA, sos_id = NA, registry_url = NA)
) %>%
distinct(owner, investor_label_lvl2, .keep_all = TRUE)
You should get a readout in the console of where the process stands as it’s running.
In a few seconds, you should see your new investors_clean dataset in your Environment pane.
Now we’re ready to match!
Wrapping up
There’s a lot of code here, and you don’t have to understand it all now.
But the most important part to understand is that we’ve created a reproducible workflow using a few custom functions and code that we can run again and again – even if we discover new holding companies and subsidiaries to add to our list.
And we’ve followed a few best practices that should make fact-checking easier on the backend.
Want to learn more about our methodology? Take a look at our write-up here.